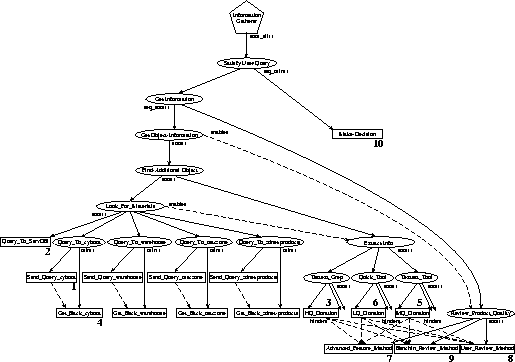
To provide a more concrete example of how BIG operates, let us walk through a sample run. The domain for this example is word processing software, where a client uses the system to find the most appropriate package, given a set of requirements and constraints. A complete high-level execution trace for this example is shown in Figure 3. The query process begins with a user specifying search criteria, which includes such elements as the duration and cost of the search as well as desired product attributes, such as genre, price, quality and system requirements. In this example, the client desires to search for a word processor for the Macintosh costing no more than 200 dollars, and would like the search process to take about ten minutes and cost less than five dollars. The user also describes the importance of product price and quality by assigning weights to these product categories, in this case the client specified a 50/50 split between price and quality. Space precludes an in depth discussion of the product quality fields, but they include items like usefulness, future usefulness, stability, value, ease of use, power, and enjoyability.
Once these parameters are specified the query begins. The task assessor starts the process by first analyzing the user's parameters and then, using its knowledge about RESUN's problem solving options and its own top-down understanding of reasonable ways to go about performing the task, it generates a TÆMS task structure believed to be capable of achieving the query. Although not used in this example, knowledge learned in previous problem solving episodes may be utilized during this step by querying a database of previously discovered objects and incorporating this information into the task structure. The task structure produced for our example query can be seen in Figure 4. Note that sets of outcomes are associated with each method, where each outcome has a probability of occurring and is described statistically via discrete probability distributions in terms of quality, cost, and duration. This detail is omitted from the figure for clarity.
Once constructed, the task structure is passed to the scheduler which makes use of the user's time and cost constraints to produce a viable run-time schedule of execution. Comparative importance rankings of the search quality, cost and duration, supplied by the client, are also used during schedule creation. The sequence of primitive actions chosen by the scheduler for this task structure is also shown in Figure 4. The numbers near particular methods indicate their assigned execution order. Again, space precludes a detailed schedule with its associated probability distributions.
The schedule is then passed to the RESUN planner/executor to begin the process of information gathering. As seen in Figure 3, retrieval in this example begins by submitting a query to a known information source called ``cybout''. While this information is being retrieved, a second query is made and completed to the local server database information source. This second action results in 400 document descriptions being placed on the blackboard, from which three are selected for further action. These three documents are then retrieved and processed in turn with a high-quality, high-duration sequence of information extraction tools. Before actual processing takes place, a quick search of each document's content for the product genre provides a cheap method of ensuring relevance - we envision this document preclassification step becoming more involved in the future. Three objects, one from each document, are found during the high-quality examination and placed on the blackboard. By this time, the initial query to cybout has completed and is retrieved, which results in an additional 61 documents being posted to the blackboard. Six more documents are then selected and retrieved for medium-quality, medium-duration extraction/processing. Four of these, though, fail the product genre search test and are discarded before processing takes place. Examination of the remaining two reveals two more products, which are added to the blackboard. A similar low-quality, low-duration process then adds two more objects.
At this point the system has a total of seven competing product objects on the blackboard which require more discriminating information to make accurate comparisons. To do this, three known review sites are queried for each object, each of which may produce data which is added to, but not combined with, the existing data for a given object (discrepancy resolution of extracted data is currently handled at decision time). After this, the final decision making process begins by pruning the object set of products which have insufficient information to make an accurate comparison. The data for the remaining objects is then assimilated, with discrepancies resolved by generating an average, each point being weighted by the quality of the source. A final product quality is then computed for each object, taking into account the gathered information, the quality of this information and the user's requirements. From this set the product with the highest expected quality is selected as the final recommendation. A confidence measure of this decision is also calculated based on the quality of each product and the certainty of the information. This information can be seen for several trials in Figure 5
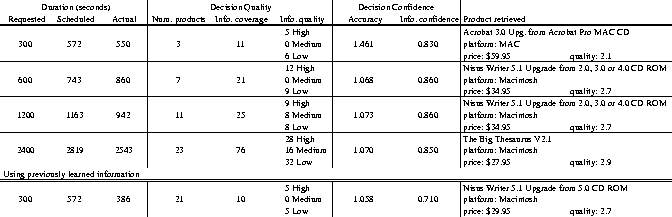 |
Looking at Figure 5 in more detail one can obtain a reasonable view of how the system operates under different time constraints. In the first column of data we can see information relating to the duration of each search. Given is the user's requested duration, the duration expected by the schedule produced from the task structure and the actual execution time. Discrepancies may arise between the requested and scheduled times because of both how the task assessor creates the task structure and how the scheduler interprets it. For instance, valid 10 minute runs were available in the 600 second query, but a 743 second path was chosen because of its greater likelihood of producing high quality results. This sort of time/quality tradeoff is controlled in part by the parameters set in the user interface. The differences seen between the scheduled and actual time is caused simply by the fact that it is difficult to accurately predict the response time of remote services in the face of capricious network traffic.
The decision quality column reflects the number and qualities of the information sources used to generate the final decision. This attribute is based on the number of products considered, the number of documents used to obtain information and the quality rankings of these pages. The quality of the retrieved documents is based on knowledge about the quality of the source, which is generated by prior human examination. Unknown sites are ranked as medium quality. The product number and information coverage values increase given more scheduled time, as one would expect. The information quality values, however, may seem un-intuitive, since medium and low quality sources were used despite the fact that the quality of the information contained is known a priori. Such sites may be selected for retrieval for two reasons: they may respond quickly, and our set of tools may be able to analyze them particularly well. So a number of such sources may be used relatively cheaply, and still be useful when examined in conjunction with a high-quality source.
The decision confidence values describe how confident the system is in the information extraction and decision making processes. Information accuracy, supplied by the information processing tool, is the degree of belief that the actual extracted information is correctly categorized and placed in the information objects. Information confidence, generated by the decision maker, reflects the likelihood that the selected product is the optimal choice given the set of products considered. This value is based on the quality distributions of each product, and represents the chance that the expected quality is correct. It should be noted that both these values are not dependent on the scheduled time. The accuracy does not change because our current information extraction tools do not produce different results with more execution time. Decision confidence, on the other hand, is based on the quality of the individual products, which are independent of execution time themselves, thus making the confidence independent.
The final decision of which product to recommend represents the sum of all these earlier efforts. The successes and failures of earlier processes are thus manifested here, which may lead to unpredictable results. For instance, in the five minute run, the system suggests that Adobe Acrobat will fulfill the client's word processing needs. This sort of error can be caused by the misinterpretation of an information source. Specifically, the phrase ``word processing'' was found associated with this package in a product description, which caused it to be accidentally included in the list of possible products. The subsequent 10 and 20 minute runs produced more useful results, both recommending the same word processor. After 40 minutes, though, the system has again selected a non-word processing package. This was also caused by a misunderstood product description, and was compounded by the fact that it was low-cost and well reviewed. It should also be noted, though, that the second and third place packages in this run were both highly rated word processors, namely ClarisWorks Office and Corel WordPerfect.
The final 5 minute query was performed after the 40 minute run, and made use of the previously generated objects when creating the initial task structure. These objects were also used to initially seed the object level of the RESUN blackboard. In this final search, more information was found on these objects, which decreased the expected quality of the 40 minute search's erroneously selected product, The Big Thesaurus, to 2.3 from 2.9. This small amount of extra information was sufficient for the system to discount this product as a viable candidate, which resulted in a much better recommendation in a shorter period of time, i.e., the recommendation of Nisus Writer. One may also see a dramatic difference when comparing these results with the initial 5 minute query, which had similar information coverage but many fewer products to select from, which produced a lower quality decision and selected a non-word processor product.