

Next: BIG in Action
Up: BIG: A Resource-Bounded Information
Previous: Information Gathering as Interpretation
The overall BIG
agent architecture is shown in Figure 2. The
agent is comprised of several
sophisticated components that are complex problem problem-solvers and
research subjects in their own rights. The integration of such complex
components is a benefit of our research agenda. By combining
components in a single agent, that have hereto been used individually,
we gain new insight and discover new research directions for the
components. The most important components, or component groups, follow in
rough order of their invocation in the BIG agent.
Figure:
The BIG Agent Architecture
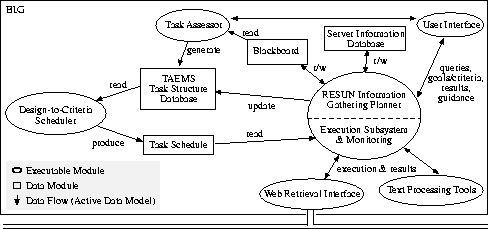 |
- Task Assessor
- The task assessor is responsible for formulating
an initial information gathering plan and then for revising the plan
as new information is learned that has significant
ramifications for the plan currently being executed. The task assessor is
not the execution component nor is it the planner that actually determines
the details of how to go about achieving information gathering goals;
the task assessor
is a component dedicated to managing the high-level view of the information
gathering process and balancing the end-to-end top-down approach of the
agent scheduler (below) and the opportunistic bottom-up RESUN planner
(also below).
The task assessor receives an initial information gathering goal
specification from an external decision maker, which can be a human or
another sophisticated automated component, and then formulates a family
of plans for gathering the necessary information. The task assessor has a
model of the goals that can be achieved by the RESUN planner and the
performance characteristics and parameters of the actions that RESUN will
employ to achieve the goals. The task assessor combines this knowledge
with previously learned information stored in the server and object
databases (below) and generates a set of plans that
delineates alternative ways to go about gathering the information and
characterizes
the different possibilities statistically in three dimensions
quality, cost, and duration, via discrete
probability distributions. The task assessor encodes the plans
in the TÆMS [7] generic, domain-independent task modeling
framework. The TÆMS models then serve
as input to the agent scheduler and other agent control components that will
be added in the future (e.g., a multi-agent coordination module).
- Object Database
- Used initially by the task assessor when determining
possible courses of action, the object database is also used by the RESUN
planner during information
gathering sessions. As the planner creates information objects
they are stored in the object database for use during future information
gathering sessions. The stored objects may be incomplete and may have
uncertainties attached to them, however, the uncertainties and
incompletions can be filled in the next time the object is used to address
a query. Through the object database and the server information database
(below), BIG learns during problem solving. Information and resources
learned and discovered are stored for subsequent information gathering
activities. The issue of aging stored data and a detailed discussion
on learning are beyond the scope of this paper.
- Server Information Database
- The server database is used by the task assessor to help generate
its initial list of information gathering options and again during the
actual search process by the RESUN planner when the information gathering
activities actually take place. The database is used to seed the initial
search and queried as new products are discovered.
The database contains records identifying both primary and
secondary information sources on the Web. Accompanying the sources
are attributes that describe the sources' retrieval times and costs, their
quality measures (see below), keywords relevant to the sources, and
other related items. The database is constructed by an offline Web
spider and modified during the search process to reflect newly discovered
sites and data. This object has information aging concerns similar to those
of the object database.
- Modeling Framework
- The TÆMS [7] task modeling language
is used to hierarchically model the information gathering process and enumerate
alternative ways to accomplish the high-level gathering goals.
The task structures probabilistically describe the quality, cost,
and duration characteristics of each primitive action and specify both
the existence and degree of any interactions between tasks and
primitive methods. For instance, if the task of
Find-Competitors-for-WordPerfect overlaps with the task of
Find-Competitors-for-MS-Word (particular bindings of the general
Find-Competitors-for-Software-Product task) then the relationship
is described via a mutual facilitation and a degree of
the facilitation specified via
quality, cost, and duration probability distributions. TÆMS task
structures are stored in a common repository and serve as a domain
independent medium of exchange for the domain-independent agent control
components; in the single agent implementation of BIG, TÆMS is primarily
a medium of exchange for the scheduler, below, the task assessor, and the
RESUN planner.
- Design-to-Criteria Scheduler
- Design-to-Criteria [14,15] is a domain independent
real-time, flexible computation [10,5,13]
approach to task scheduling. The Design-to-Criteria task scheduler reasons
about quality, cost, duration and uncertainty trade-offs of different courses
of action and constructs custom satisficing schedules for achieving the
high-level goal(s). The scheduler provides BIG with the ability
to reason about the trade-offs of different possible information gathering
and processing activities, in light of the client's goal specification (e.g.,
time limitations), and to select a course of action that best fits the
client's needs and the current problem solving context. The scheduler
receives the TÆMS models generated by the task assessor as input and
the generated schedule is returned to the RESUN planner for execution.
- RESUN Planner
- The RESUN [3,4] (pronounced ``reason'') blackboard
based planner/problem solver directs information gathering activities. The
planner receives an initial action schedule from the scheduler and then
handles information gathering and processing activities.
The strength of the RESUN planner is that it
identifies, tracks, and plans to resolve sources-of-uncertainty (SOUs)
associated with blackboard objects, which in this case correspond to
gathered information and hypothesis about the information. For example,
after processing a software review, the planner may pose the hypothesis that
Corel Wordperfect is a Windows95 wordprocessor, but associate a SOU with that
hypothesis that identifies the uncertainty associated with the extraction
technique used. The planner may then decide to resolve that SOU by using
a different extraction technique or finding corroborating evidence elsewhere.
RESUN's control mechanism is fundamentally opportunistic - as new evidence
and information is learned, RESUN may elect to work on whatever particular
aspect of the information gathering problem seems most fruitful at a given
time. This behavior is at odds with the end-to-end resource-addressing
trade-off centric view of the scheduler, a view necessary for BIG to
meet deadlines and address time and resource objectives. Currently
RESUN achieves a subset of the possible goals specified by the task assessor,
but selected and sequenced by the scheduler. However, this can leave little
room for opportunism if the goals are very detailed, i.e., depending on the
level of abstraction RESUN may not be given room to perform opportunistically
at all. This is a current focus of our integration effort. In the near term
we will complete a two-way interface between RESUN and the task assessor (and
the scheduler) that will enable RESUN to request that the task assessor
consider new information and replan the end-to-end view accordingly.
Relatedly, we will support different levels of abstraction in the
plans produced by the task assessor (and selected by the scheduler) so we can
vary the amount of room left for RESUN's run-time opportunism and
study the benefits of different degrees of opportunism within the
larger view of a scheduled sequence of actions.
- Web Retrieval Interface
- The retriever tool is the lowest level interface between the problem
solving components and the Web. The retriever fills retrieval requests by
either gathering the requested URL or by interacting with with
both general (e.g., InfoSeek), and site specific, search engines.
Through variable remapping, it provides a generic, consistent interface
to these interactive services, allowing the problem solver to pose
queries without knowledge of the specific server's syntax.
In addition to fetching the requested URL or interacting with the specific
form, the retriever also provides server
response measures and preprocesses the html document, extracting other URLs
possibly to be explored later by the planner.
- Information Extractors
- The ability to process retrieved documents
and extract structured data is essential both to refine search activities
and to provide evidence to support BIG's decision making
For example, in the software product domain, extracting a list of features
and associating them with a product and a manufacturer is critical for
determining whether the product in question will work in the user's computing
environment, e.g., RAM limitations, CPU speed, OS platform, etc.
BIG uses several information extraction techniques to process
unstructured, semi-structured, and structured information. The information
extractors are implemented as knowledge sources in BIG's RESUN planner and
are invoked after documents are retrieved and posted to the blackboard.
The information extractors are:
- textext-ks
- This knowledge source processes unstructured text documents
using the CRYSTAL [9] information extraction system to
extract particular desired data.
The extraction component uses a combination of learned domain-specific
extraction rules, domain knowledge, and knowledge of sentence construction to
identify and extract the desired information. This component is a heavy-weight
NLP style extractor that processes documents thoroughly and identifies
uncertainties with extracted data.
- grep-ks
- This featherweight KS scans a given text document looking
for a keyword that will fill the slot specified by the planner. For example,
if the planner needs to fill a product name slot and the document contains
``WordPerfect'' this KS will identify WordPerfect as the product, via
a dictionary, and fill the product description slot.
- cgrepext-ks
- Given a list of keywords, a document and a product
description object, this middleweight KS locates the context of the
keyword (similar to paragraph analysis), does a word for word comparison with
built in semantic definitions thesaurus and fills in the object accordingly.
- tablext-ks
- This specialized KS extracts tables from html documents,
processes the entries, and fills product description slots with the
relevant items. This KS is trained to extract tables and identify table
slots for particular sites. For example, it knows how to process the
product description tables found at the Benchin review site.
- quick-ks
- This fast and highly specialized KS is trained to identify and
extract specific portions of regularly formatted html files. For example,
many of the review sites use standard layouts.
- Decision Maker
- After product information objects are constructed
BIG moves into the decision making phase. In the future, BIG may determine
during decision making that it needs more information, perhaps to resolve
a source-of-uncertainty associated with an attribute that is the
determining factor in a particular decision, however, currently BIG uses the
information at hand to make a decision. Space precludes full elucidation of
the decision making process, however, the decision is based on a utility
calculation that takes into account the user's preferences and weights
assigned to particular attributes of the products and the confidence level
associated with the attributes of the products in question.
Currently, all of these components are implemented, integrated, and
undergoing testing. However, we have not yet fully integrated all
aspects of the the RESUN planner at this time. In terms of
functionality, this means that while the agent plans to gather information,
analyzes quality/cost/duration trade-offs, gathers the information,
uses the IE technology to break down the unstructured text, and then reasons
about objects to support a decision process, it does not respond
opportunistically to certain classes of events. If, during the search process,
a new product is discovered, the RESUN planner may elect to expend energy
on refining that product and building a more complete definition, however,
it will not generate a new top down plan and will not consider allocating
more resources to the general task of gathering information on products.
Thus, while the bindings of products to planned tasks are dynamic, the
allocations to said tasks are not. This integration issue is currently
being solved. We return to this issue later in the paper.
Next: BIG in Action
Up: BIG: A Resource-Bounded Information
Previous: Information Gathering as Interpretation
Thomas A. Wagner
1/26/1998