Agent-Based Information Gathering Example
We now describe a short sample run of the BIG system. The client is a student who uses the system to find a word processing package which will most closely satisfy a set of requirements and constraints. The entire run is split into the following processes: querying, planning, scheduling, retrieval, extraction and decision making.
Query processing is initiated when the client specifies and submits the search criteria, which includes the duration and cost of the search as well as desired product attributes such as price, quality features and system requirements. In this example the client is looking for a word processing package for a Macintosh costing no more than $200, and would like the search process to take ten minutes and the search cost to be less than five dollars. The client also describes the importance of product price and quality by assigning weights to these product categories, in this case the client specified that relative importance of price to quality was 60/40. Product quality is viewed as a multi-dimensional attribute with features like usefulness, future usefulness, stability, value, ease of use, power and enjoyability constituting the different dimensions. These are assigned relative weights of importance.
Once the query is specified, the task assessor starts the process of analyzing the client specifications. Then, using its knowledge of RESUN's problem solving components and its own satisficing top-down approach to achieve the top level goal, it generates a TÆMS task structure that it finds most capable of achieving the goal given the criteria (a task structure is akin to a process plan for achieving a particular task). Although not used in this example, knowledge learned in previous problem solving instances may be utilized during this step by querying the database of previously discovered objects and incorporating this information into the task structure. The task structure produced for our sample query is shown in Figure 2.
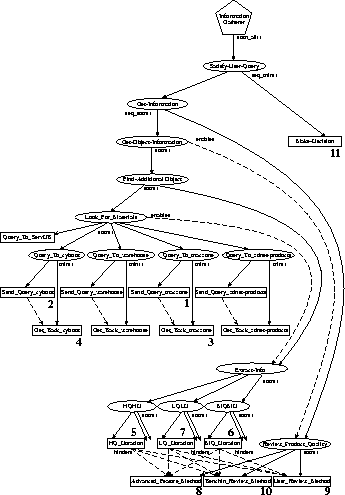
The task structure is then passed to the scheduler which makes use of the client's time and cost constraints to produce a viable run-time schedule of execution. Comparative importance rankings of the search quality, cost and duration, supplied by the client are also used during schedule creation. The sequence of primitive actions chosen by the scheduler for this task structure is also shown in Figure 2. The numbers near particular methods indicate their assigned execution order.
The schedule is then passed to the RESUN planner/executor to begin the process of information gathering. Retrieval in this example begins by submitting a query to a known information source, MacZone (www.zones.com), a computer retailer. While this information is being retrieved, a second query is made to another retailer site, the Cyberian Outpost (www.cybout.com). Generally, queries to such sites result in a list of URLs where each URL is accompanied by a small amount of text describing the full document. This information is combined with the query text and any other knowledge the agent has about the document to form a document description object that is then put on the RESUN blackboard for consideration by other knowledge sources. The query to MacZone results in 53 document descriptions being placed on the blackboard, while the Cyberian Outpost query results in an additional 61 document descriptions being added to the blackboard. Out of these candidate document descriptions, three are chosen for HighQualityHighDuration(HQHD) processing. The choice is made heuristically and is based on recency of information in the document, length of the document and its source site (some sites are preferred over others). The URLs for the three documents are:
http://www.cybout.com/cgi-bin/product_info?item=21624
http://www.zones.com/oasis/bin/catproduct.dll?product_id=85354.0
http://www.zones.com/oasis/bin/catproduct.dll?product_id=90262.0
The three documents are then retrieved and run through a document classifier to determine if they are indeed word processor products; the two documents retrieved from the Mac Zone site are rejected by the classifier. One of the rejected documents is a children's educational package to further reading and writing skills - though this package includes a text editor, the document contains enough non-word processor related verbiage to enable the classifier to correctly reject it as a word processing product. The other product is a word processor / drawing package bundle produced by Corel. The rejection of this document is somewhat dubious, however, as the document emphasizes the integration of the applications and features of the drawing product, the determination of whether or not the classifier helped to focus processing in this case is somewhat subjective. We discuss the classifier in greater detail in the next section. The sole remaining (unrejected) document is posted on the blackboard for further consideration and processing; the document is:
Nisus: Nisus Writer 5.1 Upgrade from 2.0, 3.0 or 4.0
Nisus Writer 5.1, Powerful Word Processor - Designed to Simplify.
Manufacturer #:N5190D
$54.95
Description: With version 5.1, Nisus Writer is designed to
simplify your word processing tasks more than ever.
Features and Benefits:
Intuitive Interface - We redesigned the menus, making the interface more
intuitive. All the power features are right there, easily accessible, even
for a novice user.
Improved Footnotes - Now you can use marking, cross-referencing, indexing
and Find/Replace in Footnotes as part of your main document.
Easier Find/Replace - We made all the features of PowerFind Pro available in
PowerFind and we simplified the dialog, so that even a novice user can
easily execute complex searches. We added new wild cards like Any HTML Tag,
Any Paragraph etc...You can define custom Find/Replace expressions and save
them on a menu. You can even do a "summary" search that creates a listing of
exactly where your search expression appears.
Macros - Build macros directly from search expressions with a simple click
in the Find/Replace dialog.
Form Paragraph - Remove all the extra Returns from text e-mailed to you with
one simple command.
Keyboard Shortcuts - Our famous three character keyboard shortcuts are more
flexible than ever (the use of the Command key is optional) and can be
assigned with simple keystrokes.
Background Colors - Assign background colors to your documents from our new
color picker.
Repeat Command - A handy "Repeat last menu Command" has been added to the
Edit Menu to save you time.
WYSIWYG font - WYSIWYG font menus appear instantaneously and you can add to
and access fonts in your system without having to restart Nisus Writer.
Advanced window display - These options make it easier to navigate between
files.
MacOS 8 Support - Nisus Writer 5.1 takes advantage of the new Mac OS system
with full compatibility with the Appearance Manager.
Product Requirements
Subsequent to being posted on the blackboard, a HighQualityHighDuration(HQHD) text extraction process is performed on the document. The process involves using quickext-ks , cgrep-ks and textext-ks in sequence to create an information object that models the product. An abbreviated version of the object follows:
Product Name : Nisus Writer 5.1
Company Name : Nisus
Price : $54.95
Processor : Macintosh Mac 68030
Platform : Macintosh
Processing Accuracy(Degree of Belief): range(0.0-1.0)
GENRES=0 PRODUCTID=0.8 COMPANYID=1.0 PRICE=1.0
PROCESSOR=0.8 DISKSPACE=0 PLATFORM=0.7
Of the 101 remaining candidate document descriptions, four more are selected from the blackboard for MediumQualityMediumDuration(MQMD) processing. The documents are retrieved and classified. Of the four documents, two candidates remain after document classification and filtering. The MQMD text extraction process run on both documents, which involves quickext-ks followed by cgrep-ks, does not result in extractions which are of acceptable certainty values and hence no new objects are created. In other words, the extraction failed so poorly that the extracted information was not added to existing objects or used to create new objects. The search now further proceeds with seven candidate document descriptions being selected from the blackboard for LowQualityLowDuration(LQLD) processing. Out of these, two remain after retrieval and classification. A LQLD extraction process, namely the quickext-ks, is run on the two documents resulting in the creation of the following two information objects:
Site: http://www.cybout.com/cgi-bin/product_info?item=30271
Product Name : Corel WordPerfect 3.5 - ACADEMIC
Company name : Corel
Price : $29.95
Platform : Mac/PwrMac
Processing Accuracy(Degree of Belief):
GENRES=0 PRODUCTID=0.8 COMPANYID=1.0 PRICE=1.0
PROCESSOR=0.8 DISKSPACE=0 PLATFORM=0.8
Site: http://www.cybout.com/cgi-bin/product_info?item=21623
Product Name : Nisus Writer 5.1 Upgrade from 5.0 CD-ROM
Company Name : Nisus
Price : $29.95
Platform : Macintosh
Processing Accuracy(Degree of Belief):
GENRES=0 PRODUCTID=0.8 COMPANYID=1.0 PRICE=1.0
PROCESSOR=0.6 DISKSPACE=0 PLATFORM=0.8
At this point the system has a total of three competing product objects on the blackboard which require more discriminating information to make accurate comparisons. The system has, in effect, discovered three competing word processing products and will now adapt its processing to focus on these products.
The object which is an upgrade is immediately filtered out since the client did not specify an interest in product upgrades. To discriminate between the two objects that remain, three known review sites are queried for reviews and information on each object. The extracted information is added to the the object, but not combined with existing data for the given object (discrepancy resolution of extracted data is currently handled at decision time). For each review processed, each of the extractors generates a pair, denoted < Product Quality, Search Quality > in the information objects pictured below. Product Quality denotes the quality of the product as extracted from the review (in light of the client's goal criteria), and Search Quality denotes the quality of the source producing the review. For example, if a review raves about a set of features of a given product, and the set of features is exactly what the client is interested in, the extractor will produce a very high value for the Product Quality member of the pair. However, if said review is associated with a very poor site - perhaps one that is known for inflated opinions, the Search Quality member of the pair will be very low. The two objects post-review-processing follow:
Site:http://www.cybout.com/cgi-bin/product_info?item=21624
Product Name : Nisus Writer 5.1
Company Name : Nisus
Price : $54.95
Processor : Macintosh Mac 68030
Platform : Macintosh
overall quality:-0.2857143
Usefulness: -1 Future Usefulness: 2 Ease of Use: -1 Power: 1
Stability: -1 Enjoyability:0 Value: 0
Processing Accuracy(Degree of Belief):range(0.0-1.0)
GENRES=0 PRODUCTID=0.8 COMPANYID=1.0 PRICE=1.0
PROCESSOR=0.8 DISKSPACE=0 PLATFORM=0.7
Review Consistency:
<Product Quality, Search Quality> =
<3.7142856, 2>,<-0.2857143,3>
Site: http://www.cybout.com/cgi-bin/product_info?item=30271
Product Name : Corel WordPerfect 3.5 - ACADEMIC
Company name : Corel
Price : $29.95
Platform : Mac/PwrMac
Overall Quality:1.1428572 Usefulness:2
Future Usefulness:2 Ease of Use:2 Power:1
Stability:2 Enjoyability:1 Value:1
Processing Accuracy(Degree of Belief):
GENRES=0 PRODUCTID=0.8 COMPANYID=1.0 PRICE=1.0
PROCESSOR=0.6 DISKSPACE=0 PLATFORM=0.8
Review Consistency :
<Product Quality, Search Quality> =
<1.1428572,2>,<2,1>,<0.42857143,1>
After this the final decision making process begins by first pruning the object set of products which have insufficient information to make accurate comparisons. The data for the remaining objects is then assimilated. Discrepancies are resolved by generating a weighted average of the attribute in question where the weighting is determined by the quality of the source. The Decision Maker determines which product should be recommended to the client as one which best satisfies the specifications. The Decision Maker looks at every qualifying object and computes a total score which represents the degree to which the product satisfies the client's query. Since each product has several features crucial for the decision process, such as price, quality, reliability of information sources, the score represents all these features based on how important it is to the client (determined by the weights assigned by the client). For instance the overall score takes on this form
Besides the recommendation of the best product and information about all other qualifying products, BIG also provides an evaluation of its own decision process to the client. Decision evaluation includes two factors, the decision quality and decision confidence. Decision quality is a 3-dimensional vector, namely <Number of Products, Information Coverage, Information Quality>.

- Number of Products
- is the number of qualified competing products that the agent has found. The more products the agent has to choose among, the higher is the quality of the decision.
- Information Coverage
- is the total number of documents the agent has processed. As Information Coverage increases, so does decision quality.
- Information Quality
- is the number of documents weighted by their source, namely high quality sources, medium quality sources, and low quality sources respectively.
Decision confidence is a 2-dimension vector < Information Accuracy, Information Confidence >
- Information Accuracy
- measures the accuracy of document processing. Since information extracting process is not perfect for any document, the information extractors provide the degree of beliefs in their extractions. Information accuracy is a weighted average of the degree of beliefs of each feature of the product.
- Information Confidence
- is the measure which determines how closely the recommended product satisfies client specifications. This is computed from the score distribution of products.
In our sample run the object selected by the Decision Maker was Corel WordPerfect3.5 We should note that BIG did not differentiate the academic version of WordPerfect from the commercial version; this is important because the recommendation of the academic version of WordPerfect is not valid when the client is not a student. In fact, in this short sample trace BIG was not given sufficient time to discover the commercial version of the product. If BIG is given the same query with a larger time allotment it will generally discover the non-academic version of the products and for a test case where BIG is given 20 minutes to search for information, BIG recommends the commercial version rather than the academic version. Since academic pricing is more than an occasional issue in our searches, we should rectify the situation by adding a heuristic text processing method that identifies the academic edition keywords and appropriately tags the object / price so that such products are considered only in cases where academic products are valid.